從模型到上下文
AI 工具的每一個元件——Model、記憶、指令、技能、外部連線、代理——最終都會影響 AI 能「記住」與「處理」多少資訊。理解上下文(Context Window)的機制,是真正掌握 AI 能力邊界的關鍵。
- Model:所有功能的核心引擎,能力決定上限
- AGENTS.md 與 Memory:定義 AI 的工作規則與個人化偏好
- Commands:用一個指令觸發完整流程,減少重複輸入
- Skills:賦予 AI 可重複套用的專業執行能力
- MCP:讓 AI 主動連接外部世界
- Agent:自主規劃並執行任務
- Context Window:AI 的工作記憶,理解其機制是管理大型任務的關鍵
Model(AI 模型)
一句話來說:Model 決定 AI 能做到多深、多準、多快。
Model 是所有功能的核心引擎。選擇模型時,以下面向會直接影響後續功能的表現:
- Context Window 大小:決定單次對話能處理多少內容
- 工具呼叫(Tool Use)支援:Agent 和 MCP 功能仰賴模型能否正確呼叫外部工具
- 推理能力:影響 Agent 規劃任務、分解問題的品質
- 多模態支援:部分任務需要模型能處理圖片、文件等非文字輸入
- 費用與速度:能力越強,通常費用越高、回應越慢
使用 Agent、MCP 等進階功能前,先確認所選模型是否支援對應能力。
AGENTS.md 與 Memory(記憶系統)
一句話來說:AGENTS.md 負責定義共同規則,Memory 負責累積持續可用的偏好。
AGENTS.md(各工具名稱不同,如 CLAUDE.md,但 AGENTS.md 已成為業界最通用的慣例)是靜態的,定義團隊共同遵守的規則,每次對話皆生效。
建議包含的內容:
- 專案概述
- 建置和測試命令
- 程式碼風格指南
- 測試說明
- 安全考量
部分工具還支援依情境自動判斷是否載入規則檔,例如依當前開啟的檔案類型或目錄決定套用哪些規則。
Memory 是動態的,記住使用者偏好、專案慣例等個人化資訊,跨對話持續沿用。各工具的累積方式不同,有些由 AI 自動寫入,有些需手動觸發。
使用時機:團隊共同規範寫入 AGENTS.md;個人化偏好或實作經驗交給 Memory 累積。
Commands(自訂指令)
一句話來說:Commands 解決的是「怎麼快速把需求說清楚」。
以 / 開頭的快捷指令,本質是預寫好的 prompt 模板,告訴 AI「要做什麼」。分為兩種:
- 系統內建:工具預設提供的指令,如
/help、/clear - 自訂指令:由使用者或團隊自行定義,將複雜工作流程打包成一個指令,統一協作標準
例如 /translate 背後的 prompt 模板可能是:「將以下內容翻譯成繁體中文,保留原有格式與專有名詞」。
Skills(技能)
一句話來說:Skills 解決的是「AI 要用什麼專業方法做事」。
Skills 是封裝了指引、方法與資源的可重用執行模組,讓 AI 能以一致的方式完成特定類型的任務。
與外部連線工具不同,Skills 資料夾的 Resources 是靜態的本地資源(文件範本、規格說明、參考資料),搭配可在本地執行的腳本(Scripts),聚焦於本地端的任務執行,不依賴外部網路連線。
Skills 教導 AI 如何以可重複的方式完成特定任務,例如依照統一規範建立文件、使用特定工作流程分析資料,或自動化重複性任務。
觸發方式分兩種:AI 執行任務時自動判斷呼叫(判斷 Skill 的 description),或使用者以 / 指令主動觸發。
常見範例:
/vue-best-practices:以 Vue 3 Composition API 最佳實踐撰寫程式碼/tdd:以測試驅動開發流程撰寫功能,先寫測試再實作/code-review:依統一標準對程式碼進行安全性、可維護性審查
使用時機:需要讓 AI 以一致方式重複完成特定任務時,將流程封裝成 Skill。
MCP(Model Context Protocol)
一句話來說:MCP 讓 AI 從只能聊天,變成能連接外部系統做事。
讓 AI 直接與外部服務互動的開放標準介面。沒有 MCP,AI 只能被動處理你貼進來的內容;有了 MCP,AI 可以主動查資料、操作其他系統,無需手動複製貼上。
常見 MCP Server:
- GitHub:操作 issue、PR、repository
- PostgreSQL / SQLite:查詢資料庫
- Slack:讀取訊息、發送通知
- Puppeteer / Chrome DevTools:自動化瀏覽器操作
- Google Drive / Notion:讀取文件與筆記
注意事項:
- 非官方的第三方 Server 需確認來源可信、程式碼公開可審查
- 敏感資料應確認 MCP Server 的讀寫權限設定是否符合預期
- MCP 呼叫會帶來額外的上下文與成本開銷,計費方式依工具實作而異
MCP 並不是唯一可以連接外部系統的方法,有些 APP 有提供 cli 功能可以使用,cli 很適合 ai 使用也是很好的選擇,例如 GitHub CLI
Agent(智能代理)
一句話來說:Agent 是把「思考」和「執行」串起來的自動化工作者。
Agent 是能自主規劃並依序執行多步驟任務的 AI。給定目標後,Agent 自行決定該做什麼、用哪些工具、依照什麼順序執行。複雜任務可拆分成多個子代理(subagent)平行處理,各自有獨立的 context;部分工具也支援為不同階段指定不同模型,例如規劃階段用高推理模型、執行階段改用快速模型。
常見類型:
- Plan agent:規劃實作步驟,分析架構與拆解任務
- 研究 agent:蒐集資料、搜尋文件
- 執行 agent:寫程式碼、修改檔案、執行測試
注意事項:
- 自主性越高,誤操作風險越高——任務描述中明確指定邊界(如「只讀取,不修改」)
- 執行大型任務前,先確認 AI 的規劃步驟是否合理
- 每個子代理都消耗獨立的 token 配額,複雜任務的成本需事先評估
Context Window(上下文)
一句話來說:上下文決定 AI 一次能記住多少資訊。
Context Window 是 AI 在單次對話中能處理的最大內容量,包含對話歷史、AI 回覆、讀入的檔案、工具呼叫結果等。超出上限後,AI 可能無法存取較早的內容,導致忘記最初需求或早期上下文被擠掉。
Context 的組成:
- System Prompt:AGENTS.md、Skills 載入的指引,以及工具的定義說明;在每次對話開始時就已佔用固定的 token 配額
- Tools(工具呼叫):AI 每次呼叫工具的請求與工具回傳的結果,均會計入 context;任務涉及多輪工具呼叫時,這部分的 token 消耗會持續累積
- User Messages(對話歷史):每一輪對話中使用者的輸入與 AI 的回覆,隨對話進行逐步累積
- Resources:MCP Server 提供的即時資料、本地 Skills 的靜態資源、讀入的檔案內容,以及其他注入的參考資訊
理解各部分的佔比,有助於在遇到 context 不足時,針對性地進行清理或壓縮。
值得注意的是,context 並非越長越好——**Context Rot(上下文腐化)**研究顯示,隨著 token 數量增加,模型性能會變得不穩定:單個干擾項就會降低性能,多個干擾項會複合衰退;模型也不會均勻使用所有上下文,這是長對話後 AI 表現變差的主因。(參考:Context Rot — Chroma Research)
管理方式
日常操作層面,當 context 不足或對話變長時的因應方式:
- 切換任務:執行
/new開啟全新對話,確保 context 乾淨 - 拆分任務:將大任務拆成多個小任務分開執行
- 使用 subagent:讓子代理處理子任務,各自有獨立的 context
- 手動壓縮:部分工具提供壓縮指令(如 Claude Code 的
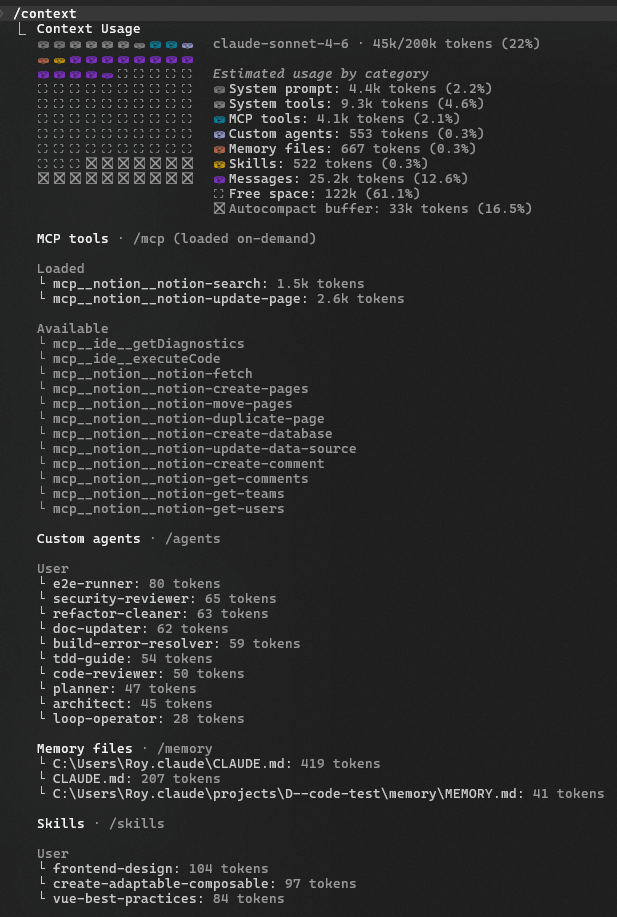
/compact)提前釋放空間 - 查看用量:部分工具提供查看各類別 token 佔用的介面
Context Engineering(上下文工程)
設計層面,在任務開始前主動規劃 context 結構,目標不是填滿 context,而是「在對的時機提供對的資訊、以對的格式呈現」。Anthropic 提出幾個實際做法:
- Just-in-Time 載入:維護輕量的檔案路徑或查詢,在執行時才透過工具動態載入需要的資料,而非預先把所有內容塞進 context
- 壓縮(Compaction):對話接近上限時,將歷史摘要後重新起一個乾淨的 context,保留架構決策等關鍵資訊,丟棄冗餘的工具輸出
- 子代理架構:由多個專注子代理各自處理子任務,每個子代理回傳簡短摘要(1,000–2,000 token),主代理再進行整合,避免單一 context 過載
除此之外,Plan 先行也是常見的實踐:執行前先進入規劃模式(Plan Mode),讓 AI 在不消耗執行 context 的情況下分析任務、確認方向,待規劃確認後再開始執行,避免因方向錯誤浪費大量 context。
以下截圖展示了某工具的 Context Window 用量介面,可看到各類別(系統提示、工具、訊息等)佔用的 token 比例: